
朋友在某国企从事宣传相关工作,经常需要在微博上发布推文,同时要做工作留痕,需要将每天发布的推文整理进excel中去,由于没有编程经验,他只能人肉地一条一条将数据录入,费事费力费手还费眼睛,稍不留意还会复制错。某天在感叹人生时,热心的xiaoma决定帮帮他,帮他解放双手,自由飞翔。
需求明确
需求主要分为两点:
- 需要微博推文的详细信息,主要包含三个字段:发布时间、微博正文、文章地址
- 根据自定义时间范围进行爬取
| 发布时间 | 完整文本 | 微博链接 | |
|---|---|---|---|
| 2023/06/01 08:30 | 人生最重要的不是所站的位置,而是所朝的方向。早安,加油! | https://weibo.com/xxxxxxxxxx/xxxxxxxxx |
准备工作
首先老规矩,先F12打开控制台,看看数据源是从哪里传来的。
新浪微博基本上没有啥反爬策略,数据源一下就找到了。可以看到,个人主页的文章是通过 https://weibo.com/ajax/statuses/mymblog?uid=个人id&page=1&feature=0 来传递的,基于这个链接,可以发现通过控制uid和page这两个参数,来获取需要爬取的内容。
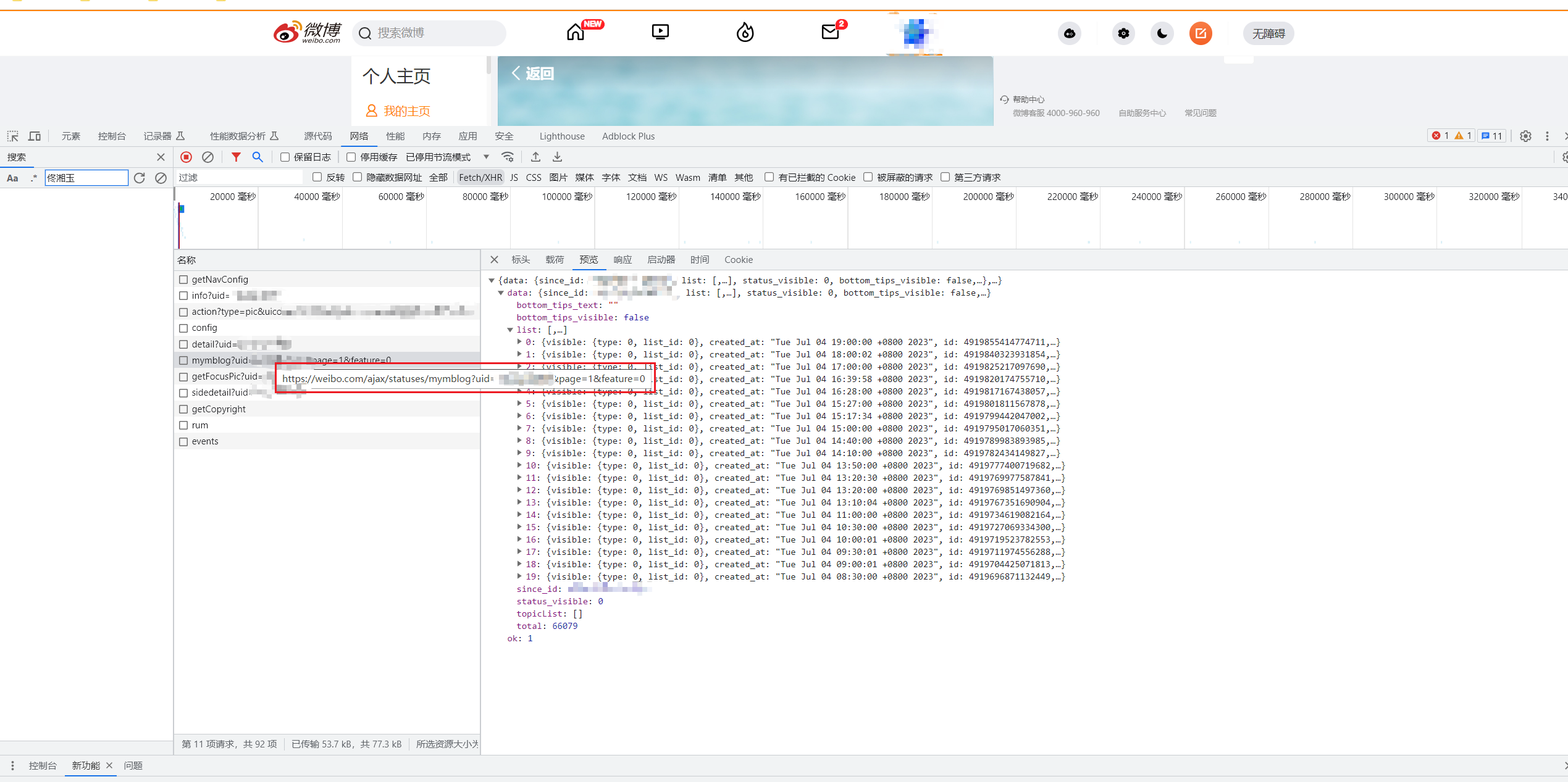 用户主页数据源
用户主页数据源
但是跟朋友了解到,当微博正文的字数过多时,需要点击展开全文才能获取到全部内容。于是我确定找一篇这样的微博,看看长微博是否需要从其他链接获取数据。 果不其然,从text_raw这个字段可以看到原始文章被截断了,如下图所示:
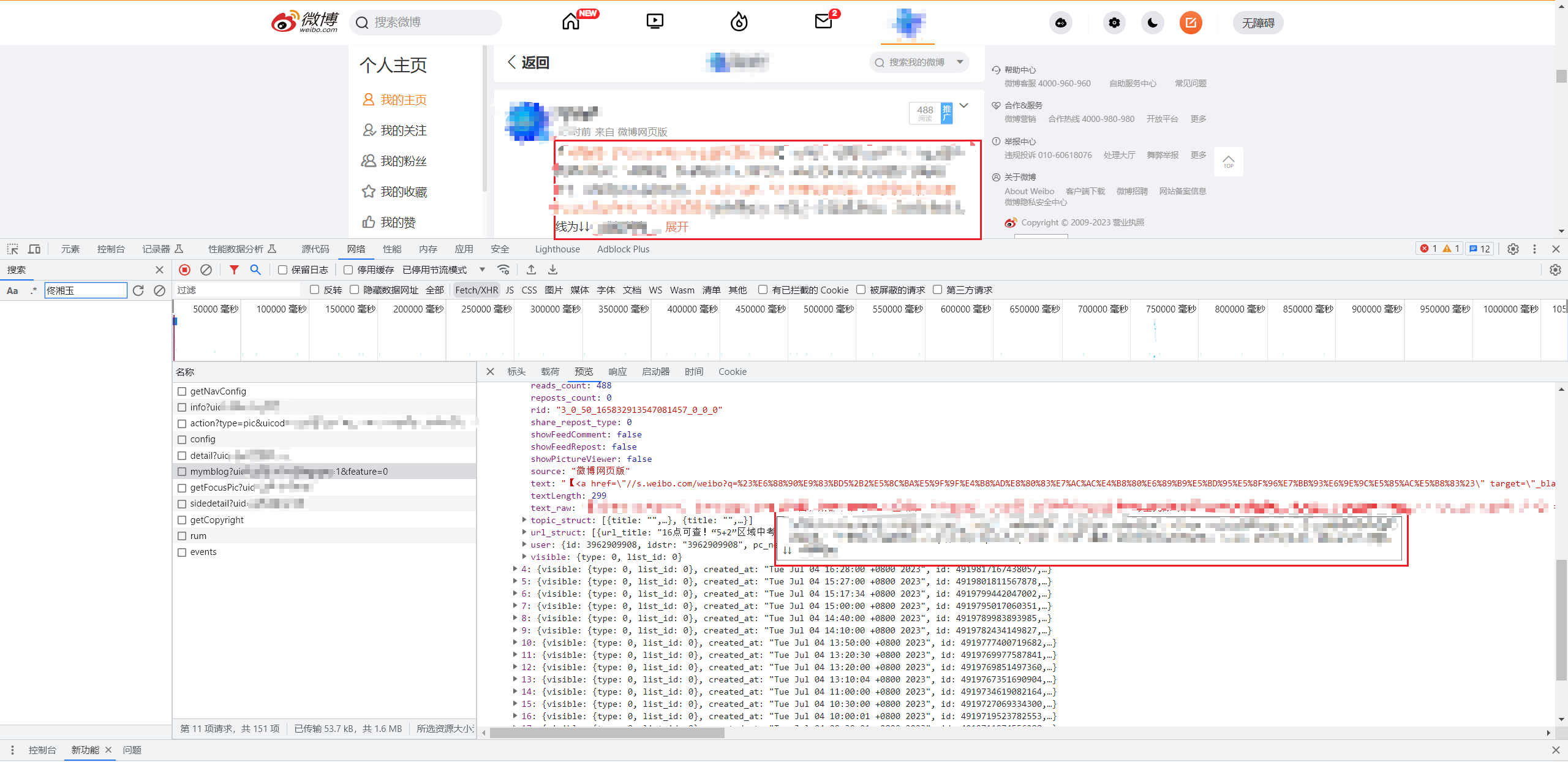 长微博返回报文
长微博返回报文
那话不多说,点一下站看,抓取一下原始正文数据源。啪,很快啊,一下子就找到了。可以发现长微博是对应的数据源地址为 https://weibo.com/ajax/statuses/longtext?id=文章id ,通过id这个参数来获取不同长微博的内容,而这个id则对应上面数据源报文里的myblogid这个字段。
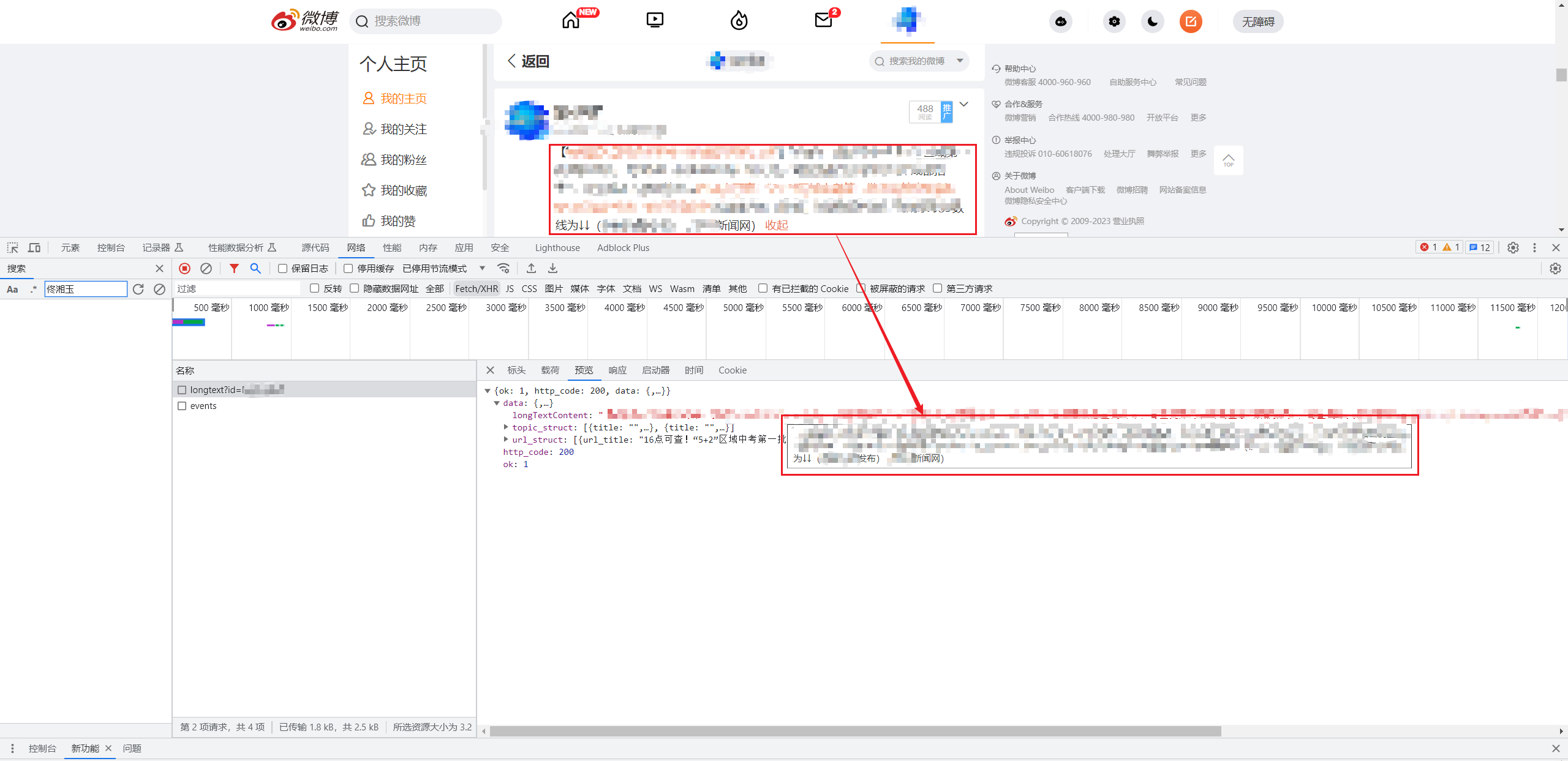 长微博数据源
长微博数据源
这样一来,数据源有了,下面就开始通过python爬虫,将数据爬取下来。
爬虫实现
老规矩
首先根据老规矩,引入基础的HTTP请求头。
1
2
3
4
5
6
7
8
9
10
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
'cookie': 'SINAGLOBAL=1658874181562.7039.1644829575113; UOR=,,www.baidu.com; ULV=1684587618293:4:1:1:6237551181889.782.1684587618255:1672196231808; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5H5Wh_m0Z1bFeVLUBSfnH45JpX5KMhUgL.Foe4Soz4eh.4ehn2dJLoIEBLxK-L12qL12eLxKqLBo-L1h2LxKqL1-eL12BLxK-L122LBK2t; XSRF-TOKEN=1SuDPwkaGrVFiUFHvVF_joFf; ALF=1688452936; SSOLoginState=1685860936; SCF=Aj8oQ05eWw5NZ61wfpgbvYDdTzIcFetULfWmOA6AQAROSFvqH6Chq2mPVT5ovOw2VK6g9Xebj9Hc2Zm-RB5EopA.; SUB=_2A25JeEIZDeRhGeVH7VAY8CfFyzSIHXVqDDTRrDV8PUNbmtAGLUngkW9NTypFYkQzyX_T85XrFfUmmP3FXOhZnJYn; WBPSESS=u3cyzfM6DCx6pdS5XFnW9eJQCXXbQb3Tiv0I20kayuhNcXkxIbtr22y71ogUjqpPMqTokj6h5Jf7mkCbzg9UJ1ny98j1jmXqnV0nAL5HckHmA5sx0O7XuKe2p3l3KGWVJj64SJDM2jYwbZQhc2VLKw=='
}
url = 'https://weibo.com/ajax/statuses/mymblog?'
params = {
'uid': '222222222', # 用户id
'page': page,
'feature': '0'
}
获取正文
通过第二步获取的数据源链接,进行request请求,获取微博文章数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def get_blog_info(response_json,i):
"""
从响应 JSON 中解析出用户信息。
:param response_json: 响应 JSON 对象
:return: 包含用户信息的字典
"""
blog = response_json['data']['list'][i]
data = {
'URL地址': blog['mblogid'], # 微博URL后缀地址
'发布时间': blog['created_at'], #发布时间
'发布日期': blog['created_at'],
'正文文本': blog['text'], #微博前台显示文本,用于判断是否有长文本
'完整文本': blog['text_raw'], # 微博全文,若正文文本含有‘展开’,需访问单独链接获取全文
'微博链接': 'https://weibo.com/用户id/' + blog['mblogid'] #微博完整URL
}
# 判断前台显示文本,用于判断是否有长文本,有则需要访问单独链接获取全文
if data['正文文本'].find('<span class=\"expand\">展开</span>') != -1:
url2 = 'https://weibo.com/ajax/statuses/longtext?id='+ data['URL地址']
response2 = requests.get(url2, headers=headers).json()
data['完整文本'] = response2['data']['longTextContent']
else:
data['完整文本'] = data['完整文本']
return data
日期处理
由于微博正文返回的json数据中,发布时间采用的是中国标准时间格式,所以还需要对发布时间进行单独处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
def trans_format(time_string, from_format, to_format='%Y.%m.%d %H:%M'):
"""
@note 时间格式转化
:param time_string:
:param from_format:
:param to_format:
:return:
"""
time_struct = time.strptime(time_string,from_format)
times = time.strftime(to_format, time_struct)
return times
def get_blog_info(response_json,i):
"""
从响应 JSON 中解析出用户信息。
:param response_json: 响应 JSON 对象
:return: 包含用户信息的字典
"""
blog = response_json['data']['list'][i]
data = {
'URL地址': blog['mblogid'], # 微博URL后缀地址
'发布时间': blog['created_at'], #发布时间
'发布日期': blog['created_at'],
'正文文本': blog['text'], #微博前台显示文本,用于判断是否有长文本
'完整文本': blog['text_raw'], # 微博全文,若正文文本含有‘展开’,需访问单独链接获取全文
'微博链接': 'https://weibo.com/用户id/' + blog['mblogid'] #微博完整URL
}
# 调用trans_format函数,对发布时间由中国标准时间转换为yyyy-mm-dd格式
cst_time = data['发布时间']
data['发布时间'] = trans_format(cst_time,'%a %b %d %H:%M:%S +0800 %Y', '%Y/%m/%d %H:%M')
data['发布日期'] = trans_format(cst_time,'%a %b %d %H:%M:%S +0800 %Y', '%Y/%m/%d')
# 判断前台显示文本,用于判断是否有长文本,有则需要访问单独链接获取全文
if data['正文文本'].find('<span class=\"expand\">展开</span>') != -1:
url2 = 'https://weibo.com/ajax/statuses/longtext?id='+ data['URL地址']
response2 = requests.get(url2, headers=headers).json()
data['完整文本'] = response2['data']['longTextContent']
else:
data['完整文本'] = data['完整文本']
保存内容
爬取下来后,还需要对数据进行持久化,保存到本地。
1
2
3
4
5
6
7
8
def save():
# 保存结果
df = pd.DataFrame(res[::-1]) # 按照发布时间倒序排列
df = df.sort_values(by='发布时间',ascending=True,inplace=False)
day = time.strftime("%Y-%m-%d", time.localtime())
writer = './'+ day + '.xlsx'
df[['发布日期','发布时间','完整文本','微博链接']].to_excel(excel_writer=writer, sheet_name=day, index=[0])
print('\n')
完善代码
经过一番折腾,整个爬虫的主体逻辑已经差不多了,但前面提到,还需要能够根据指定的时间范围来进行数据的爬取,所以还需要稍稍加一点参数进行控制,来实现这个功能。 过程不是很复杂,直接上完整代码了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
import requests
import time
import pandas as pd
def trans_format(time_string, from_format, to_format='%Y.%m.%d %H:%M'):
"""
@note 时间格式转化
:param time_string:
:param from_format:
:param to_format:
:return:
"""
time_struct = time.strptime(time_string,from_format)
times = time.strftime(to_format, time_struct)
return times
def get_blog_info(response_json,i):
"""
从响应 JSON 中解析出用户信息。
:param response_json: 响应 JSON 对象
:return: 包含用户信息的字典
"""
blog = response_json['data']['list'][i]
data = {
'URL地址': blog['mblogid'], # 微博URL后缀地址
'发布时间': blog['created_at'], #发布时间
'发布日期': blog['created_at'],
'正文文本': blog['text'], #微博前台显示文本,用于判断是否有长文本
'完整文本': blog['text_raw'], # 微博全文,若正文文本含有‘展开’,需访问单独链接获取全文
'微博链接': 'https://weibo.com/用户id/' + blog['mblogid'] #微博完整URL
}
# 调用trans_format函数,对发布时间由中国标准时间转换为yyyy-mm-dd格式
cst_time = data['发布时间']
data['发布时间'] = trans_format(cst_time,'%a %b %d %H:%M:%S +0800 %Y', '%Y/%m/%d %H:%M')
data['发布日期'] = trans_format(cst_time,'%a %b %d %H:%M:%S +0800 %Y', '%Y/%m/%d')
# 判断前台显示文本,用于判断是否有长文本,有则需要访问单独链接获取全文
if data['正文文本'].find('<span class=\"expand\">展开</span>') != -1:
url2 = 'https://weibo.com/ajax/statuses/longtext?id='+ data['URL地址']
response2 = requests.get(url2, headers=headers).json()
data['完整文本'] = response2['data']['longTextContent']
else:
data['完整文本'] = data['完整文本']
return data
def main(page,start_date,end_date):
global weibo
response = requests.get(url=url,params=params, headers=headers).json()
length = len(response['data']['list'])
for i in range(length):
blog_info = get_blog_info(response,i)
print('正在爬取第{}页第{}条'.format(page,i+1))
print('-----------------------')
if blog_info['发布日期'] < start_date: # 微博文章是按最新的进行展示的,所以档当前微博发布时间小于开始时间,就停止爬取
weibo = 0
return weibo
if blog_info['发布日期'] <= end_date:
print(blog_info)
print('\n')
res.append(blog_info)
time.sleep(0.5)
def save():
# 保存结果
df = pd.DataFrame(res[::-1])
df = df.sort_values(by='发布时间',ascending=True,inplace=False)
day = time.strftime("%Y-%m-%d", time.localtime())
writer = './'+ day + '.xlsx'
df[['发布日期','发布时间','完整文本','微博链接']].to_excel(excel_writer=writer, sheet_name=day, index=[0])
print("第{}页爬取完毕".format(page))
print('\n')
%timeit
if __name__ == "__main__":
res = []
weibo = 1
page = 1
start_date = trans_format(input('请输入开始日期,格式:20230521:'),'%Y%m%d', '%Y/%m/%d')
end_date = trans_format(input('请输入结束日期,格式:20230521:'),'%Y%m%d', '%Y/%m/%d')
while weibo:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
'cookie': 'SINAGLOBAL=1658874181562.7039.1644829575113; UOR=,,www.baidu.com; ULV=1684587618293:4:1:1:6237551181889.782.1684587618255:1672196231808; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5H5Wh_m0Z1bFeVLUBSfnH45JpX5KMhUgL.Foe4Soz4eh.4ehn2dJLoIEBLxK-L12qL12eLxKqLBo-L1h2LxKqL1-eL12BLxK-L122LBK2t; XSRF-TOKEN=1SuDPwkaGrVFiUFHvVF_joFf; ALF=1688452936; SSOLoginState=1685860936; SCF=Aj8oQ05eWw5NZ61wfpgbvYDdTzIcFetULfWmOA6AQAROSFvqH6Chq2mPVT5ovOw2VK6g9Xebj9Hc2Zm-RB5EopA.; SUB=_2A25JeEIZDeRhGeVH7VAY8CfFyzSIHXVqDDTRrDV8PUNbmtAGLUngkW9NTypFYkQzyX_T85XrFfUmmP3FXOhZnJYn; WBPSESS=u3cyzfM6DCx6pdS5XFnW9eJQCXXbQb3Tiv0I20kayuhNcXkxIbtr22y71ogUjqpPMqTokj6h5Jf7mkCbzg9UJ1ny98j1jmXqnV0nAL5HckHmA5sx0O7XuKe2p3l3KGWVJj64SJDM2jYwbZQhc2VLKw=='
}
url = 'https://weibo.com/ajax/statuses/mymblog?'
params = {
'uid': '22222222', # 用户id
'page': page,
'feature': '0'
}
main(page,start_date,end_date)
page += 1
time.sleep(5)
print('全部爬取完毕!!!\n')
save()
print('全部保存完毕!!!')
问题总结
爬虫实现后,我简单爬取了最近两周的数据,发现部分页会超出20条数据。经过研究后发现,如果是第三方访问某一微博用户的主页,该用户的主页会展示其转发推广的微博,导致这个page的数据超过20条。但本着人生本就不完美的原则,我决定让朋友将cookie替换成自己账号的cookie,这样就不会有这样的问题出现了,我可真是个小机灵鬼捏!!!